Mar 13: ETL
Манипуляции с таблицами
reshape (Advanced)
Обычная форма представления данных в таблицах — когда одна строка является одним наблюдением, а в значениях колонок отражены те или иные характеристики этого наблюдения. Такой формат традиционно называется wide-форматом, потому что при увеличении количества характеристик таблица будет расти вширь, путем увеличения числа колонок. Пример таблицы в wide-формате.
library(data.table)
# создаем таблицу с идентификатором респондента, его возрастом, ростом и весом
dt_wide <- data.table(
wave = paste0('wave_', rep(1:2, each = 2)),
id = paste0('id_', rep(1:2)),
age = c(45, 68, 47, 69),
height = c(163, 142, 164, 140),
weight = c(55, 40, 50, 47))
dt_wide## wave id age height weight
## 1: wave_1 id_1 45 163 55
## 2: wave_1 id_2 68 142 40
## 3: wave_2 id_1 47 164 50
## 4: wave_2 id_2 69 140 47Тем не менее, нередко встречается другой формат, в котором на одно наблюдение может приходиться несколько строк (по количеству измеренных характеристик этого наблюдения). В таком случае таблица состоит из колонки, в которой содержится какой-то идентификатор объекта, одной или нескольких колонок, в которых содержатся идентификаторы характеристик объекта, и колонки, в которой содержатся значения этих характеристик. Такой формат называется длинным, long-форматом данных, потому что при увеличении количества измеряемых характеристик таблица будет расти в длину увеличением строк.
# создаем таблицу с идентификатором респондента, его возрастом, ростом и весом
dt_long <- data.table(
# две волны, по два респондента в каждой
wave = paste0('wave_', rep(1:2, each = 6)),
# на каждого респондента задаем три строки
id = paste0('id_', rep(rep(1:2, each = 3), 2)),
# три характеристики повторяем для четырех респондентов
variable = rep(c('age', 'height', 'weight'), 4),
# задаем значения характеристик, с учетом того, как упорядочены первые две колонки
value = c(45, 163, 55,
68, 142, 40,
47, 164, 50,
69, 140, 47))
dt_long## wave id variable value
## 1: wave_1 id_1 age 45
## 2: wave_1 id_1 height 163
## 3: wave_1 id_1 weight 55
## 4: wave_1 id_2 age 68
## 5: wave_1 id_2 height 142
## 6: wave_1 id_2 weight 40
## 7: wave_2 id_1 age 47
## 8: wave_2 id_1 height 164
## 9: wave_2 id_1 weight 50
## 10: wave_2 id_2 age 69
## 11: wave_2 id_2 height 140
## 12: wave_2 id_2 weight 470.0.0.1 dcast()
Для того, чтобы трансформировать long-формат в wide-формат, используется функция dcast() пакета data.table (либо cast() пакета reshape2). Также можно использовать функцию reshape() из базового набора функций R, однако эта функция достаточно медленная по скорости работы.
Для того, чтобы превратить созданную выше таблицу в long-формате в широкий формат, выражение будет выглядеть следующим образом (сама операция называется решейп):
dcast(data = dt_long, formula = wave + id ~ variable, value.var = 'value')## wave id age height weight
## 1: wave_1 id_1 45 163 55
## 2: wave_1 id_2 68 142 40
## 3: wave_2 id_1 47 164 50
## 4: wave_2 id_2 69 140 47Здесь аргумент data - определяет таблицу, которую мы хотим трансформировать.
Аргумент formula задает, что в результирующей таблице будет задавать уникальное наблюдение, и значения какой колонки будут разделены на самостоятельные колонки. Формулу можно прочитать как строки ~ колонки в результирующей таблице. В нашем случае уникальное наблюдение мы задаем парой переменных wave и id, поэтому мы их указываем до тильды через +. Колонки же мы создаем по значениям переменной variable, после тильды. Следует отметить, что ситуация, когда строка задается несколькими переменными через оператор +, весьма частая, а вот в правой части формулы несколько переменных встречаются достаточно редко, обычно все же на колонки раскладывают по значениям одной переменной.
Аргумент value.var содержит текстовое название переменной, значения которой будут отражены в результирующей таблице по колонкам для каждого наблюдения.
Иногда случаются ситуации, когда необходимо провести сначала агрегацию по одной из колонок, описывающих наблюдение. Например, вычислить средние значения возраста, роста и веса для каждой волны. Это можно сделать в два этапа - сначала провести агрегацию, и потом решейп. Также можно сразу сделать решейп, и воспользоваться дополнительным аргументом fun.aggregate, который сразу, при решейпе, агрегирует данные. Например, если использовать сначала агрегацию, а потом трансформацию в wide-формат:
# агрегируем наблюдения по волнам и характеристикам
tmp <- dt_long[, list(value = mean(value)), by = list(wave, variable)]
tmp## wave variable value
## 1: wave_1 age 56.5
## 2: wave_1 height 152.5
## 3: wave_1 weight 47.5
## 4: wave_2 age 58.0
## 5: wave_2 height 152.0
## 6: wave_2 weight 48.5
# трансформируем в wide-формат. колонки id уже нет в таблице, поэтому удаляем из формулы
dcast(data = tmp, formula = wave ~ variable, value.var = 'value')## wave age height weight
## 1: wave_1 56.5 152.5 47.5
## 2: wave_2 58.0 152.0 48.5Аналогично, но с использованием аргумента fun.aggregate. В значения аргумента передаём название функции без кавычек и скобок, в нашем случае это fun.aggregate = mean:
dcast(data = tmp, formula = wave ~ variable, value.var = 'value', fun.aggregate = mean)## wave age height weight
## 1: wave_1 56.5 152.5 47.5
## 2: wave_2 58.0 152.0 48.50.0.0.2 melt()
Обратная трансформация также возможна, из wide-формата в long-формат. Для этого используется функция melt():
melt(data = dt_wide,
id.vars = c('wave', 'id'),
measure.vars = c('age', 'height', 'weight'),
variable.name = 'variable',
value.name = 'value')## wave id variable value
## 1: wave_1 id_1 age 45
## 2: wave_1 id_2 age 68
## 3: wave_2 id_1 age 47
## 4: wave_2 id_2 age 69
## 5: wave_1 id_1 height 163
## 6: wave_1 id_2 height 142
## 7: wave_2 id_1 height 164
## 8: wave_2 id_2 height 140
## 9: wave_1 id_1 weight 55
## 10: wave_1 id_2 weight 40
## 11: wave_2 id_1 weight 50
## 12: wave_2 id_2 weight 47Здесь аргумент id.vars задает переменные, которые будут использоваться для уникальной идентификации наблюдения. Аргумент measure.vars определяет те колонки, которые войдут длинную таблицу как значения переменной характеристик наблюдений (когда каждая строка — отдельная характеристика наблюдения, несколько строк на одного пользователя). Аргументы variable.name и value.name задают, соответственно, названия колонок характеристик наблюдения и значений этих характеристик в финальной таблице.
Чтение файлов SPSS
Для импорта файлов SPSS (.sav) обычно используют функции какого-либо из двух пакетов - foreign::read.spss(), который идет в базовом наборе пакетов R, а так же haven::read_spss(), авторства Хэдли Викхэма.
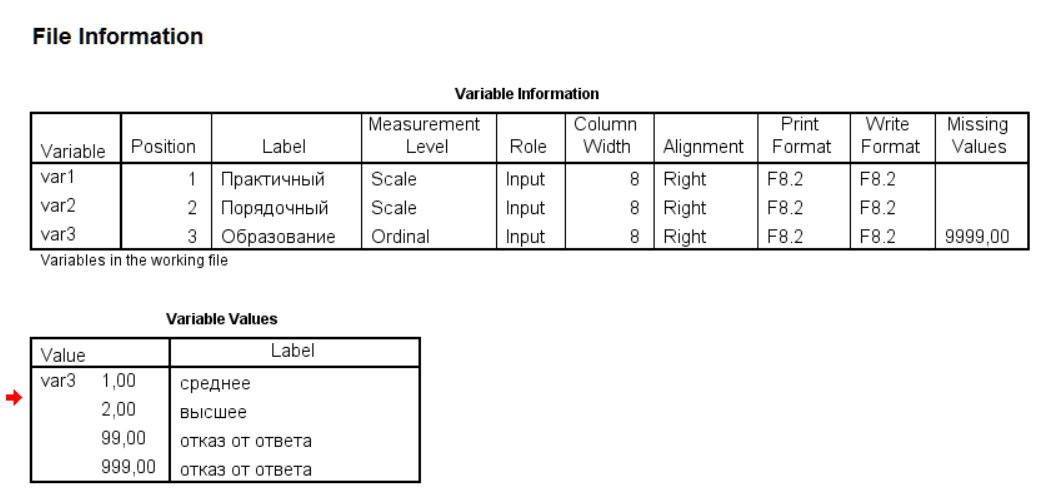
Функции read_sav() и read_spss() пакета haven обладают схожим с foreign::read.spss() функционалом при меньшем количестве настроек. При этом эти функции несколько быстрее, а так же не имеют проблем с длинными строками. В результате импорта получается tibble-таблица (так как haven принадлежит экосистеме tidyverse).
## # A tibble: 6 × 3
## var1 var2 var3
## <dbl> <dbl> <dbl+lbl>
## 1 3 4 1 [среднее]
## 2 4 5 NA
## 3 3 5 99 [отказ от ответа]
## 4 3 5 1 [среднее]
## 5 4 4 4
## 6 3 5 999 [отказ от ответа]Функция не имеет настроек, как импортировать значения, для которых заданы метки, и в таблице представлены числовые значения. При необходимости получить значения метки переменных или значений необходимо идти в атрибуты колонок таблицы:
str(spss_data)## tibble [6 × 3] (S3: tbl_df/tbl/data.frame)
## $ var1: num [1:6] 3 4 3 3 4 3
## ..- attr(*, "label")= chr "Практичный"
## ..- attr(*, "format.spss")= chr "F8.2"
## $ var2: num [1:6] 4 5 5 5 4 5
## ..- attr(*, "label")= chr "Порядочный"
## ..- attr(*, "format.spss")= chr "F8.2"
## $ var3: dbl+lbl [1:6] 1, NA, 99, 1, 4, 999
## ..@ label : chr "Образование"
## ..@ format.spss: chr "F8.2"
## ..@ labels : Named num [1:4] 1 2 99 999
## .. ..- attr(*, "names")= chr [1:4] "среднее" "высшее" "отказ от ответа" "отказ от ответа"Пакет haven импортирует данные в свой формат, однако полученный объект можно преобразовать в data.table:
library(data.table)
setDT(spss_data)
class(spss_data)## [1] "data.table" "data.frame"У нас есть колонка var3, для которой в SPSS были заданы метки. В полученном формате метки хранятся в атрибутах колонки — это что-то вроде мета-информации. Посмотрим все атрибуты колонки с помощью функции attributes() (иногда это проще делать через синтаксис списков и оператор $):
# смотрим атрибуты вектора-колонки var3
attributes(spss_data[, var3])## $label
## [1] "Образование"
##
## $format.spss
## [1] "F8.2"
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## среднее высшее отказ от ответа отказ от ответа
## 1 2 99 999
# через синтаксис списков
attributes(spss_data$var3)## $label
## [1] "Образование"
##
## $format.spss
## [1] "F8.2"
##
## $class
## [1] "haven_labelled" "vctrs_vctr" "double"
##
## $labels
## среднее высшее отказ от ответа отказ от ответа
## 1 2 99 999Мы видим четыре атрибута — метку переменной ($label), SPSS-формат данных ($format.spss), обозначение, что переменная в SPSS имеет метки значений ($class) и собственно вектор меток, которые используются для значений этой колонки ($labels).
Для того, чтобы сохранить метки значений (а не сами значения), можно создать новую колонку и в нее записать с результат применения функции as_factor пакета haven — эта функция извлекает и сопоставляет значения и их метки.
spss_data[, var4 := as_factor(var3)]
spss_data## var1 var2 var3 var4
## 1: 3 4 1 среднее
## 2: 4 5 NA <NA>
## 3: 3 5 99 отказ от ответа
## 4: 3 5 1 среднее
## 5: 4 4 4 4
## 6: 3 5 999 отказ от ответаКак мы видим, для значений 1, 99, 999 были проставлены метки, и они оказались в новой переменной, а не атрибутом. Для значения 4 метки не было, поэтому оно было записано именно значением.