Feb 13: data.table pt.2
dataset
library(data.table)
# импортируем по ссылке
sw <- fread('http://bit.ly/39aOUne')
# смотрим структуру объекта
str(sw)## Classes 'data.table' and 'data.frame': 77 obs. of 6 variables:
## $ name : chr "Luke Skywalker" "C-3PO" "Darth Vader" "Owen Lars" ...
## $ height : int 172 167 202 178 165 97 183 188 163 183 ...
## $ mass : num 77 75 136 120 75 32 84 84 NA NA ...
## $ skin_color : chr "fair" "gold" "white" "light" ...
## $ gender : chr "male" "n/a" "male" "male" ...
## $ planet_name: chr "Tatooine" "Tatooine" "Tatooine" "Tatooine" ...
## - attr(*, ".internal.selfref")=<externalptr>Применение функций
Простое применение функций
Функцию можно применить к колонке, тогда в результате мы получим простой вектор с результатом применения функции:
sw[, median(mass, na.rm = TRUE)]## [1] 79Функция + list()
Если применение функции обернуть в list(), то в результате мы получим не вектор с результатами применения функции, а табличку, в которой в колонке/колонках будет результат функции.
## V1
## 1: 79Полезно попутно с этим задавать название колонки - в примере ниже мы на основе таблички sw вычисляем среднее значение колонки mass и результат представляем в виде таблички с колонкой mass_md.
## mass_md
## 1: 79Количество строк и значений: .N, uniqueN
В data.table есть пара полезных функций, которые позволяет быстро и лаконично считать количество значений и количество уникальных значений.
Считаем количество строк в табличке — для этого используется функция .N (в data.table есть еще несколько функций, которые начинаются с ., но мы их почти не будем касаться).
sw[, .N]## [1] 77Функция uniqueN() считает количество уникальных значений. Аналогична сочетанию двух функций length() + unique(), просто короче и быстрее.
sw[, uniqueN(planet_name)]## [1] 48Ветвления: ifelse / fifelse
В R есть два вида ветвлений с использованием if. Первое — стандартная для многих языков конструкция if {} else{}, она используется при создании функций и т. д. Для работы с таблицами полезнее функция ifelse() или её быстрый аналог в data.table — fifelse (f от fast).
В первом аргументе функции мы указываем проверку, в результате которой можно будет сказать TRUE или FALSE. Вторым аргументом — что должно быть возвращено, если результат проверки будет TRUE (логическое утверждение из первого аргумента истинно). Третий аргумент — что должно быть возвращено, если утверждение из первого аргумента ложно. Например, мы проверяем, истинно ли, что 5 тождественно 3. Так как пять не равно трём, результатом сравнения 5 == 3 будет FALSE (утверждение ложно), соответственно, результатом ifelse() будет 'значение если неверно'.
5 == 3## [1] FALSE
ifelse(5 == 3, 'значение если верно', 'значение если неверно')## [1] "значение если неверно"Ключевое отличие ifelse() от классического if {} else{} в том, что эта функция векторизована. То есть, если в первом аргументе сравнивать вектор с каким-то значением, то проверка будет применяться к каждому элементу вектора. Соответственно, и результатов ifelse будет столько же, сколько элементов в векторе.
## [1] "значение если неверно" "значение если верно" "значение если неверно"Все это позволяет использовать ifelse/fifelse для операций над колонками — так в примере ниже мы проверяем с помощью функции grepl, встречается ли в значениях ячеек в колонке skin_color слово grey. И если встречается, то в новую колонку будет проставлено значение grey, а если не встречается - no grey.
sw[, new := fifelse(grepl('grey', skin_color), 'grey', 'no grey')]
sw[1:10, list(name, skin_color, new)]## name skin_color new
## 1: Luke Skywalker fair no grey
## 2: C-3PO gold no grey
## 3: Darth Vader white no grey
## 4: Owen Lars light no grey
## 5: Beru Whitesun lars light no grey
## 6: R5-D4 white, red no grey
## 7: Biggs Darklighter light no grey
## 8: Anakin Skywalker fair no grey
## 9: Shmi Skywalker fair no grey
## 10: Cliegg Lars fair no greyСоотношение list() и := в операциях над колонками
На занятии я заметил, что многие путаются в синтаксисе создания новых колонок и в выражении list(). Различие следующее:
sw[, new_value := 'bla-bla-bla']
sw[1:5]## name height mass skin_color gender planet_name new
## 1: Luke Skywalker 172 77 fair male Tatooine no grey
## 2: C-3PO 167 75 gold n/a Tatooine no grey
## 3: Darth Vader 202 136 white male Tatooine no grey
## 4: Owen Lars 178 120 light male Tatooine no grey
## 5: Beru Whitesun lars 165 75 light female Tatooine no grey
## new_value
## 1: bla-bla-bla
## 2: bla-bla-bla
## 3: bla-bla-bla
## 4: bla-bla-bla
## 5: bla-bla-blaЗдесь выражение sw[, new_value := 'bla-bla-bla'] можно прочитать как в таблице sw создай новую колонку new_value и запиши в неё значение 'bla-bla-bla'. Одинарное значение будет размножено по количеству строк. Вместо 'bla-bla-bla' также может быть и какая-нибудь функция, которая создаёт вектор такой же длины, сколько строк в таблице (если больше или меньше, то выдаст ошибку):
# в таблице 77 строк, поэтому можем просто указать 77:1
sw[, new_value2 := 77:1]
sw[1:5]## name height mass skin_color gender planet_name new
## 1: Luke Skywalker 172 77 fair male Tatooine no grey
## 2: C-3PO 167 75 gold n/a Tatooine no grey
## 3: Darth Vader 202 136 white male Tatooine no grey
## 4: Owen Lars 178 120 light male Tatooine no grey
## 5: Beru Whitesun lars 165 75 light female Tatooine no grey
## new_value new_value2
## 1: bla-bla-bla 77
## 2: bla-bla-bla 76
## 3: bla-bla-bla 75
## 4: bla-bla-bla 74
## 5: bla-bla-bla 73Выражение sw[, new_value2 := 77:1] можно прочитать как в таблице sw создай новую колонку new_value2 и запиши в неё вектор, который получится в результате выполнения выражения 77:1.
Конструкция с list() используется в ситуациях, когда на основе существующей таблицы надо создать новую таблицу. Фактически это создание нового списка на основе колонок таблицы, просто в результате будет таблица и класс data.table:
## total_users height_mn
## 1: 77 176.2078Здесь выражение new_dt <- sw[, list(total_users = uniqueN(name), height_mn = mean(height, na.rm = TRUE))] можно прочитать следующим образом: на основе таблицы sw создай таблицу, в которой в колонку total_users запиши количество уникальных значений из колонки name, а в height_mn - среднее значение по колонке height. Полученную таблицу запиши в объект new_dt. Надо помнить, что total_users и height_mn - это колонки, которые будут в новой таблице, в sw их нет.
Соответственно, использовать := вместе с list() некорректно. Точно также использовать знак = неправильно для создания новых колонок в уже существующей таблице, интерпретатор вернет ошибку.
.SD (Advanced)
Также можно выделить колонки таблицы data.table c помощью конструкций .SD и .SDcols. .SD служит ярлыком-указателем на колонки с которыми надо провести какое-то действие, а .SDcols - собственно вектор названий колонок или порядковых номеров колонок в таблице. Если .SDcols не указано, то подразумеваются все колонки таблицы. Оборачивать в list() конструкцию .SD не нужно.
Например:
# смотрим содержание таблицы
sw[1:5]## name height mass skin_color gender planet_name new
## 1: Luke Skywalker 172 77 fair male Tatooine no grey
## 2: C-3PO 167 75 gold n/a Tatooine no grey
## 3: Darth Vader 202 136 white male Tatooine no grey
## 4: Owen Lars 178 120 light male Tatooine no grey
## 5: Beru Whitesun lars 165 75 light female Tatooine no grey
## new_value new_value2
## 1: bla-bla-bla 77
## 2: bla-bla-bla 76
## 3: bla-bla-bla 75
## 4: bla-bla-bla 74
## 5: bla-bla-bla 73
# выделяем первую и третью колонки датасета
sw[1:5, .SD, .SDcols = c(1, 3)]## name mass
## 1: Luke Skywalker 77
## 2: C-3PO 75
## 3: Darth Vader 136
## 4: Owen Lars 120
## 5: Beru Whitesun lars 75
# выделяем эти же колонки по названиям
sw[1:5, .SD, .SDcols = c('name', 'mass')]## name mass
## 1: Luke Skywalker 77
## 2: C-3PO 75
## 3: Darth Vader 136
## 4: Owen Lars 120
## 5: Beru Whitesun lars 75.SD используется в большом количестве операций. Например, когда надо провести какую-то одну операцию над сразу несколькими колонками. Например, если мы хотим узнать, какого типа данные лежат в указанных колонках (пример искусственный, в реальности проще воспользоваться str()):
## name mass
## 1: character numericНередко .SD используется тогда, когда надо выбрать какую-то строку в группе. Например, если мы хотим получить первую строку каждой группы, мы можем это сделать следующим образом:
sw[, .SD[1], by = gender]## gender name height mass skin_color planet_name
## 1: male Luke Skywalker 172 77 fair Tatooine
## 2: n/a C-3PO 167 75 gold Tatooine
## 3: female Beru Whitesun lars 165 75 light Tatooine
## 4: hermaphrodite Jabba Desilijic Tiure 175 NA green-tan, brown Nal Hutta
## new new_value new_value2
## 1: no grey bla-bla-bla 77
## 2: no grey bla-bla-bla 76
## 3: no grey bla-bla-bla 73
## 4: no grey bla-bla-bla 51Агрегации
В синтаксисе data.table есть конструкция by, которая отвечает за применение операций над колонками отдельно для каждой группы (общая структура выглядит следующим образом: dataset[выбор строк, операции над колонками, группировка]).
Общая логика группировки стандартная: split - apply - combine. То есть датасет разделяется на блоки по значениям группирующей переменной, к колонкам каждого сабсета применяется какое-то выражение и результат обратно собирается в таблицу. Результатом группировки в data.table всегда будет таблица. 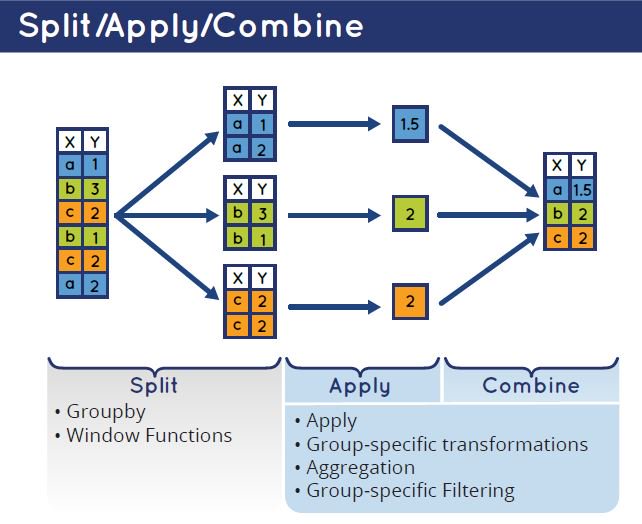
Вычисления по одной колонке
Можно использовать группировку при применении функции к таблице, но удобнее результат операции с колонкой оборачивать в list(), так как это дает возможность переименовать колонку. В примере ниже мы считаем количество уникальных значений в колонке name для каждой группы по значениям колонки gender:
sw[, uniqueN(name), by = gender]## gender V1
## 1: male 57
## 2: n/a 3
## 3: female 16
## 4: hermaphrodite 1## gender n_chars
## 1: male 57
## 2: n/a 3
## 3: female 16
## 4: hermaphrodite 1Вычисления по нескольким колонкам
Можно выполнять операции сразу с несколькими колонками:
## gender n_chars mass_md
## 1: male 57 80.0
## 2: n/a 3 32.0
## 3: female 16 52.5
## 4: hermaphrodite 1 NAГруппировка по нескольким полям
Часто возникает необходимость группировки сразу по нескольким полям — для этого колонки групп так же указываются через список. В выражении ниже мы сначала фильтруем датасет и оставляем только строки, где в колонке gender есть значения male и female, после чего в группах по полу и цвету кожи считаем количество персонажей. Результат агрегации записываем в новый объект и выводим на печать только первые 5 строк (просто чтобы сократить вывод).
sw_grps <- sw[gender %in% c('male', 'female'),
list(n_chars = uniqueN(name)),
by = list(gender, skin_color)]
sw_grps[1:5]## gender skin_color n_chars
## 1: male fair 12
## 2: male white 2
## 3: male light 4
## 4: female light 5
## 5: female fair 3Дополнительные материалы
Моя серия вебинаров по data.table. Группировки рассматриваются на первом вебинаре.
Шпаргалка по data.table. Не без нюансов, но вполне осмысленная
Для питоно-говорящих: словарь соответствий конструкций data.table и pandas
Домашнее задание
Работаем все с теми же данными, что и в предыдущем занятии.
library(data.table)
# таблица привлеченных пользователей и их стоимости
users <- fread('https://gitlab.com/upravitelev/mar201s/raw/master/data/users.csv')
str(users)## Classes 'data.table' and 'data.frame': 100 obs. of 3 variables:
## $ user_id : chr "user_1" "user_2" "user_3" "user_4" ...
## $ media_source: chr "FbAds" "FbAds" "AdWords" "Ironsource" ...
## $ cost : num 2.61 1.51 2.95 0.97 1.44 1.07 1.88 2.22 1.7 2.94 ...
## - attr(*, ".internal.selfref")=<externalptr>
# таблица платежей привлеченных пользователей
payments <- fread('https://gitlab.com/upravitelev/mar201s/raw/master/data/payments.csv')Level 1: I’m too young to die
внимательно прочитайте материалы предыдущего занятия (разделы advanced - по настроению) и разберитесь с примерами.
обновите в памяти операции над векторами (создание, простейшие манипуляции, фильтрация по номеру элемента и по значению), а так же операции с таблицами: создание, фильтрация по строкам, операции над колонками, агрегаты.
Level 2: Hey, not too rough
Импортируйте данные:
library(data.table)
# таблица привлеченных пользователей и их стоимости
users <- fread('https://gitlab.com/upravitelev/mar191s/raw/master/data/users.csv')
str(users)## Classes 'data.table' and 'data.frame': 100 obs. of 3 variables:
## $ user_id : chr "user_1" "user_2" "user_3" "user_4" ...
## $ media_source: chr "FbAds" "FbAds" "AdWords" "Ironsource" ...
## $ cost : num 2.61 1.51 2.95 0.97 1.44 1.07 1.88 2.22 1.7 2.94 ...
## - attr(*, ".internal.selfref")=<externalptr>
# таблица платежей привлеченных пользователей
payments <- fread('https://gitlab.com/upravitelev/mar191s/raw/master/data/payments.csv')
str(payments)## Classes 'data.table' and 'data.frame': 221 obs. of 2 variables:
## $ user_id: chr "user_28" "user_28" "user_28" "user_28" ...
## $ gross : num 0.755 0.37 0.38 0.33 0.286 ...
## - attr(*, ".internal.selfref")=<externalptr>в таблице payments разметьте пользователей, у которых больше 5 платежей и сумма за пять платежей превышает 20 — их обозначьте как
whales, прочих какother.Сделайте сводные статистики (количество пользователей, средний и максимальный платежи) в каждой из этих двух групп.
## is_whale n_users gross_mn gross_max
## 1: other 23 1.669462 18.52535
## 2: whales 7 2.061005 20.98412Level 3: Hurt me plenty
замените в
paymentsвсе значенияgross, которые выше 90% (90 процентиля ряда), наNA.Замените все полученные NA на медиану по ряду. Создайте отдельно колонку is_imputed, в которой будет промаркировано, замещено пропущенное значение гросса медианой или нет.
Соберите статистики, сколько пользователей платящих пользователей каждого канала, сколько исходно было у них платежей, среднее значение платежей, количество и долю импутированных от общего количества платежей, насколько среднее по импутированным платежам отличаются от исходных. Дробные значения округляйте до 2 знака.
## media_source payers transactions gross_mn imputed gross2 delta
## 1: FbAds 9 51 1.917418 5 1.321610 0.5958087
## 2: Ironsource 10 88 1.727096 10 1.081534 0.6455618
## 3: AdWords 11 82 1.883136 7 1.119504 0.7636320Level 4: Ultra-violence
NB! задания не связаны друг с другом, просто отработка разных алгоритмов.
- Отсортируйте датасет по пользователям. Создайте колонку кумулятивных платежей
gross_cumпо каждому пользователю (кумулята в рамках пользователя). Создайте колонку, в которой будет доля этого значения кумуляты от общей суммы. Вам поможет идея, что делать операции над колонками в группах можно не только при создании новой таблицы, но и при создании новых колонок.
## user_id gross gross_cum share
## 1: user_14 2.7557520 2.7557520 1.00
## 2: user_16 5.5066916 5.5066916 1.00
## 3: user_21 0.6769709 0.6769709 0.03
## 4: user_21 0.4285491 1.1055199 0.04
## 5: user_21 0.7705587 1.8760787 0.07- Создайте переменную-маркер
gross_quant, в котором будет маркировка пользователей, в каком квартиле находятся суммарные платежи пользователя. Подумайте, погуглите (напрямую задача вряд ли решается), как сделать это максимально лаконично (достаточно читаемо это можно сделать в два выражения, например).
## user_id gross gross_cum share gross_quant
## 1: user_14 2.7557520 2.7557520 1.00 Q1
## 2: user_16 5.5066916 5.5066916 1.00 Q1
## 3: user_21 0.6769709 0.6769709 0.03 Q4
## 4: user_21 0.4285491 1.1055199 0.04 Q4
## 5: user_21 0.7705587 1.8760787 0.07 Q4Level 5: Nightmare
Перезагрузите payments.
Для каждого платящего пользователя сгенерируйте метрику, на какой день от инсталла пользователь сделал платеж (округляйте до целых). Для генерации используйте
rlnorm()c meanlog = 1, sdlog = 0.5.Посчитайте сколько в среднем дней проходит между первым и третьим платежами, с разбивкой по каналам привлечения.
Сделайте все это только с одним мерджем - присоединением канала пользователя. В принципе, четырех выражений вполне хватит. Если воспользоваться некоторыми трюками и пренебречь эстетикой, то и двух.
## media_source delta_mn
## 1: FbAds 1.428571
## 2: Ironsource 0.700000
## 3: AdWords 1.125000