May 29: rvest + API
Запись занятия
Запись занятия, которое было 29 мая, можно найти здесь:
Все записи организованы в плейлист
Условные операторы
if…else
Поведение условных операторов if и else в R аналогично другим языкам: если (if) условие верно, то выполняется первое выражение, если же неверно (else), то второе. Условие else является необязательным, также в коде вполне может встретиться несколько конструкций с if, без последующего else.
Условие ветвления может быть задано как выражением, в результате которого возвращается единичное логическое TRUE/FALSE, либо же объектом с логическим значение (результат проведенной отдельно проверки). Если в условие передан численный объект, то он будет преобразован в логическое значение (0 в FALSE, все остальное в TRUE). При комбинации нескольких логических проверок, их объединяют через бинарные логические операторы && или ||.
Выражения, которые выполняются для if … else желательно заключать в фигурные скобки, даже если это однострочное выражение (и обязательно, если это несколько выражений). Также следует помнить, что оператор else должен быть на той же строчке, на которой закрывается фигурная скобка оператора if. В противном случае эти два оператора будут проинтерпретированы как независимые и R вернет ошибку.
alarm <- 2 + 2 == 5
print(alarm)## [1] FALSE## Warning: Your math is broken!!!111ifelse
Конструкция if...else обладает одним ограничением — она не векторизована. То есть, для того, чтобы проверить, допустим, каждый элемент вектора, необходимо использовать циклы. Либо же обратиться к конструкции ifelse():
x <- 1:5
ifelse(x %% 2 == 0, 'even', 'odd')## [1] "odd" "even" "odd" "even" "odd"В примере мы создаем вектор от 1 до 5, и потом, с помощью ifelse(), проверяем каждый элемент, если элемент делится на 2 без остатка, то возвращаем even, иначе же odd. Как правило, ifelse() используется для модификации значений в колонках датасетов и любых других местах, когда надо не просто по условию выполнить какое-то выражение из пары альтернатив, а быстро модифицировать вектор значений.
switch (Advanced)
Функция switch() — очень удобный вариант ветвления в ситуациях нескольких альтернатив. Согласно документации первым аргументом функции выступает строковое или численное значение. Стоит учитывать, что в зависимости от типа (строка или число) несколько меняется поведение функции. Так, если в первым аргументом передается численное значение, то функция возвращает альтернативу под таким номером, из указанного вторым и следующими аргументами списка альтернатив. Если значение первого аргумента превышает количество альтернатив, то функция ничего не вернет (точнее, вернет NULL):
switch(3,
"Amber",
"Westeros",
"Westworld",
"Cadia")## [1] "Westworld"## NULLЕсли в функцию передается строковое значение (и это наиболее частое применение), то второй и следующие аргументы — это также список альтернатив, но альтернатив именованных. Это необходимо, так как строковое значение не может быть использовано как номер альтернативы в списке. Список альтернатив должен быть именован в соответствии с допустимыми (или желаемыми) вариантами значений первого аргумента. Также можно указать одну альтернативу без имени, которая будет возвращаться по умолчанию, то есть, когда в первом аргументе будет значение, не совпадающее с названиями именованных альтернатив.
Функция switch() чаще всего используется при создании функций. В примере ниже функция poles_of_existence() возвращает вектор имен ключевых элементов вселенной “Хроник Амбера” Роджера Желязны.
# объявляем функцию
poles_of_existence <- function(pole) {
switch(
pole,
Chaos = c('Serpent', 'The Logrus', 'Suhuy', 'Courts of Chaos'),
Order = c('Unicorn', 'The Pattern', 'Dworkin Barimen', 'Amber'),
'unknown'
)
}
# вызываем имена и объекты Хаоса
poles_of_existence('Chaos')## [1] "Serpent" "The Logrus" "Suhuy" "Courts of Chaos"
# пробуем другой аргумент, которого нет в списке имен альтернатив
poles_of_existence('Westeros')## [1] "unknown"В редких случаях в функцию передается элемент сортированного вектора (фактора). В таком случае происходит конвертация типа значения в character и функция работает как со строковым значениям, несмотря на уровни фактора. Одновременно пользователю, при интерактивной работе, возвращается предупреждение. Впрочем, это достаточно редкий и вырожденный случай, который следует избегать.
Скрапинг журнала
Сбор данных статьи
Для сбора данных каждой статьи журнала мы написали функцию, которая принимает на вход адрес статьи и возвращает мета-информацию - имя автора (авторов), название статьи, аннотацию, ключевые слова и DOI.
В функции мы импортируем в рабочее окружение код web-страницы, и потом, с помощью XPATH-путей, указываем тэги с необходимой информацией и извлекаем ее из них. Так как вся интересующая нас информация находится в одной большой ячейке с классом "centercolumn", мы в путях используем эту ячейку как корневую и пропускаем все, что было до неё: //div[@class="centercolumn"].
library(rvest)
library(data.table)
get_article_info <- function(article_url) {
page <- read_html(article_url)
# автор
a_author <- html_element(page, xpath = '//div[@class="centercolumn"]/h3') %>% html_text()
# заголовок
a_title <- html_element(page, xpath = '//div[@class="centercolumn"]/h2') %>% html_text()
res <- data.table(
author = a_author,
title = a_title
# ,
# annotation = html_element(page, xpath = '//div[@class="centercolumn"]/div/p') %>% html_text(),
# keywords = html_element(page, xpath = '//div[@class="centercolumn"]/div[5]') %>% html_text(),
# doi = keywords = html_element(page, xpath = '//div[@class="centercolumn"]/div[6]') %>% html_text()
)
return(res)
}Применяем функцию:
get_article_info(article_url = "https://ecsoc.hse.ru/2021-22-2/456278364.html")## author
## 1: \n\n\t\n\t\t\n\t\t\tБессонова О. Э.\n\t\n\n\t\n\n
## title
## 1: Трансформация института административных жалоб в гражданские формыДля того, чтобы собрать информацию по рубрике, нам надо во-первых, научиться собрать информацию хотя бы по одной странице, где дан список статей (например: https://ecsoc.hse.ru/rubric/26590246_page=1_sort=author.html). Во-вторых, надо научиться собирать информацию со всех страниц рубрики, где даны списки статей. Количество страниц мы видим внизу каждой страницы рубрики.
Собирать информацию с одной страницы будем следующим образом: импортируем страницу, ищем, где на странице даны ссылки на статьи. Потом к этим ссылкам применяем написанную ранее функцию. Так как на странице рубрики материалы о статьях даны в однообразной форме, проще собрать эту информацию автоматически, в цикле или с использованием функции lapply().
main_url <- 'https://ecsoc.hse.ru/rubric/26590246_page=1_sort=author.html'
main_page <- read_html(x = main_url)
articles_on_page <- lapply(3:12, function(i) {
path <- paste('//div[@class="centercolumn"]/div[', i, ']/small/a[2]', sep = '')
url <- html_element(main_page, xpath = path) %>% html_attr('href')
# втыкаем проверку на то, есть ли ссылка на статью
if (!is.na(url)) {
art_info <- get_article_info(article_url = url)
return(art_info)
}
})Здесь 3:12 — это указатель, что функцию надо применять к ячейкам с 3 по 12 (так как на одной странице десять блоков ссылок на статьи). function(i) {} — анонимная функция, которую мы объявляем и сразу же, в lapply() применяем. В ней мы работаем с уже импортированной в рабочее окружение страницей. Поэтому основная задача — написать xpath-путь для каждого блока, для этого мы используем paste(): склеиваем кусок пути и значение итератора (который на разных циклах принимает значения от 3 до 12, как мы указали в первом аргументе lapply()). Пишем путь, извлекаем по этому пути ссылку на страницу статьи и собираем информацию по статье с помощью написанной ранее функции.
Так как не на всех страницах может быть 10 статей, то нам надо встроить дополнительную проверку: если мы действительно получили ссылку на статью, то мы собираем информацию по статье. А если нет — то идем на следующую итерацию (то есть, следующее значение из набора, указанного в первом аргументе lapply(), у нас это последовательность от 3 до 12). Такая проверка делается с помощью блока if () {} - если указанное условие истинно, то выполняется код, если нет — то ничего не выполняется.
В результате lapply() мы получаем список из нескольких табличек класса data.table (как мы помним, объект класса list может содержать другие объекты самых разных типов). Для того, чтобы собрать из списка табличек одну табличку, мы используем функцию rbindlist() пакета data.table. В результате получается табличка:
articles_on_page <- rbindlist(articles_on_page)
articles_on_page## author
## 1: \n\n\t\n\t\t\n\t\t\tBiggart N. W.\n\t\n\n\t\n\n
## 2: \n\n\t\n\t\t\n\t\t\tJagd S.\n\t\n\n\t\n\n
## 3: \n\n\t\n\t\t\n\t\t\tStark D.\n\t\n\n\t\n\n
## 4: \n\n\t\n\t\t\n\t\t\tБарсукова С. Ю.\n\t\n\n\t\n\n
## 5: \n\n\t\n\t\t\n\t\t\tБарсукова С. Ю.\n\t\n\n\t\n\n
## 6: \n\n\t\n\t\t\n\t\t\tБарсукова С. Ю.\n\t\n\n\t\n\n
## 7: \n\n\t\n\t\t\n\t\t\tБарсукова С. Ю.\n\t\n\n\t\n\n
## 8: \n\n\t\n\t\t\n\t\t\tБарсукова С. Ю.,\n\t\t\tЗвягинцев В. И.\n\t\n\n\t\n\n
## 9: \n\n\t\n\t\t\n\t\t\tБарсукова С. Ю.,\n\t\t\tКоробкова А. Д.\n\t\n\n\t\n\n
## 10: \n\n\t\n\t\t\n\t\t\tБердышева Е. С.\n\t\n\n\t\n\n
## title
## 1: Social Organisation and Economic Development
## 2: French Economics of Convention and Economic Sociology
## 3: Ambiguous Assets for Uncertain Environments: Heterarchy in Postsocialist Firms
## 4: Неформальная экономика: понятие, структура
## 5: Неформальная экономика: причины развития в зеркале мирового опыта
## 6: Теневой рынок труда и трудовое право в России (к вопросу принятия нового Трудового кодекса)
## 7: Три составных части контрафакта: подделки, серый импорт и имитаторы
## 8: Механизм «политического инвестирования», или Как и зачем бизнес участвует в выборах и оплачивает партийную жизнь
## 9:
## 10: Дифференциация «привлекательности» правонарушенийв восприятии российских полицейскихСбор информации по рубрике
Каждая рубрика содержит несколько страниц, на которых виде находятся ссылки на статьи и краткая информация по ним. Выше мы научились собирать информацию по одной такой странице, теперь надо научиться определять, сколько вообще таких страниц есть в каждой рубрике и собрать информацию по ним всем.
Получить количество страниц с списками статей мы можем простым выражением — эта информация хранится в ячейке с классом last:
# идем на первую страницу рубрики
main_url <- 'https://ecsoc.hse.ru/rubric/26590246.html'
main_page <- read_html(x = main_url)
# указываем путь к значению и извлекаем значение
n_pages_path <- '//div[@class="pageNav"]/span[@class="last"]/a'
n_pages <- html_element(main_page, xpath = n_pages_path) %>%
html_text()
# конвертируем строку в число
n_pages <- as.numeric(n_pages)
n_pages## [1] 14После того, как мы получили количество страниц, мы можем написать lapply()-выражение, в котором будем ходить по этим страницам и собирать с них ссылки на статьи и, соответственно, из этих ссылок уже собирать информацию по статьям в таблицу. Логика работы аналогична предыдущему блоку, когда собирали информацию по одной странице.
В веб-верстке, когда есть несколько страниц одного типа, как в нашем случае, иногда можно менять url-адрес простым изменением номера. То есть, https://ecsoc.hse.ru/rubric/26590246_page=1_sort=author.html для первой страницы, https://ecsoc.hse.ru/rubric/26590246_page=3_sort=author.html для третьей и так далее.
Правда, нередко первую страницу указывают и без номера. То есть, 'https://ecsoc.hse.ru/rubric/26590246.html' и https://ecsoc.hse.ru/rubric/26590246_page=1_sort=author.html должны быть идентичны, первый вариант более человекочитаем, второй — более консистентен с точки зрения верстки.
Соответственно, в lapply() в первом аргументе указываем, по каким номерам страниц мы будем ходить и собирать информацию. В нашем случае это 1:n_pages (что тождественно seq(from = 1, to = n_pages, by = 1)). В анонимной функции мы собираем адрес страницы (используя меняющееся на каждой итерации значение из первого аргумента) и импортируем эту страницу. А потом применяем уже написанный нами ранее блок сбора данных о статьях с одной страницы рубрики.
rubric_articles <- lapply(1:n_pages, function(x) {
# импортируем страницу рубрики
main_url <- paste('https://ecsoc.hse.ru/rubric/26590246_page=', x, '_sort=author.html', sep = '')
main_page <- read_html(x = main_url)
# собираем информацию по странице рубрики
articles_on_page <- lapply(3:12, function(i) {
path <- paste('//div[@class="centercolumn"]/div[', i, ']/small/a[2]', sep = '')
url <- html_element(main_page, xpath = path) %>% html_attr('href')
# втыкаем проверку на то, есть ли ссылка на статью
if (!is.na(url)) {
art_info <- get_article_info(article_url = url)
return(art_info)
}
})
articles_on_page <- rbindlist(articles_on_page, fill = TRUE)
return(articles_on_page)
})
# собираем результат в табличку
rubric_articles <- rbindlist(rubric_articles, fill = TRUE)Так как в результате мы получим список табличек по каждой странице рубрики, надо собрать их в одну большую таблицу. для этого используем также rbindlist().
JSON
JSON (javascript object notation) — один из самых распространенных форматов сообщений, с помощью которого происходит обмен данными между серверами, сервером и клиентом. Соответствующие файлы имеют расширение .json.
Структура json-объекта
json-объект легко опознать по наличию фигурных скобок, которые структурируют объект, а также по записям в кавычках, разделенным двоеточиями. Простейший пример json-объекта:
{
"name":"Loki",
"parents": {
"father":"Farbauti",
"mother":"Laufey"
}
}Пара, разделенная двоеточием — это пара ключа (названия параметра) и значения, которое передается в этом параметре. В табличках аналогом было бы название колонки и значение в ячейке. Ключ всегда указывается в двойных кавычках ("), разделитель ключа и значения — двоеточие, :. Значения могут быть разных типов, в том числе и сложные объекты (другие пары ключ: значение, множество таких пар, массивы значений и т. д.). Пара ключ:значение выделяется фигурными скобками ({}). Как правило, json-объект - это либо одна большая пара ключ-значение, притом, с большой вложенностью. Либо множество таких пар.
Типы значений:
- String — строковое значение, выделяется двойными кавычками. Пример: {"name": "Baldr"};
Number — число, как целое, так и с мантиссой (вида 1e6). Из-за слабой типизации число можно передать как число, так и как строку (5 vs “5”). Пример пары:
{"age": 19};Boolean — логическое значение, слова true и false являются зарезервированными словами для значений ИСТИННО и ЛОЖНО. Пример:
{"is_alive": false};Null — Обычно в json-объектах пропуски не передаются - проще просто не задавать такую пару, все равно при парсинге json-объекта в таблицу на это место автоматически убдет проставлен NULL. Тем не менее, в спецификации есть. Пример:
{"extra": null};Object — Практически всегда в json-ах используются в качестве значения другие неупорядоченные пары ключ:значение, набор таких пар также выделяется фигурными скобками. Таким образом реализуется иерархия данных. Пример:
"death":{"killer":"Loki", "weapon":"omela"};Array — массив значений какого-то типа. Массив выделяется квадратными скобками, значения внутри массива разделяются запятыми: [1, 2, 3], [“a”, “b”]. Значениями массива такде могут быть и другие json-объекты (пары или множества пар ключ:значение). Пример, когда значением является массив json-объектов, каждый из который содержит две пары ключ:значение:
{
"parents": [
{"name": "Odin", "group":"aesir"},
{"name": "Frigg", "group":"aesir"}
]
}Импорт json-файлов в R
Для импорта json-файлов в R чаще всего используется пакет jsonlite и две его функции:
fromJSON() — в большинстве случаев
stream_in() — изредка встречается формат njson (есть некоторые различия в структуре объекта, расширение все то же), для парсинга которого рекомендуется использовать эту функцию.
При импорте json-объекта в R объект может быть импортирован как таблица (как правило, в редких случаях, когда json-объект плоский и не содержит вложений), чаще все же импортируется как объект класса список (list), то есть, именованный список с подсписками. Доступ к элементам списка классический, с помощью операторов [[ и [. Впрочем, проще и надежнее использовать доступ по оператору $ — из-за того, что практически всегда в json-объектах есть ключ, то в импортированном json-е этот ключ становится названием подсписка.
Допустим, у нас есть вот такой json-файл. По факту это массив из двух json-объектов.
cat ./data/test.json## [{
## "name":"Thor",
## "parents": {
## "father":"Odin",
## "mother":"Jord"
## },
## "weapon": "Mjölnir"
## },
## {
## "name":"Loki",
## "parents": {
## "father":"Farbauti",
## "mother":"Laufey"
## }
## }]При импорте он может быть импортирован как таблица (потому что оба вложенных json-объекта одинаковой длины). При импорте каждый из этих объектов будет обработан как строка в табличке. Ключи объектов задают колонки, значения — строки. Так как для ключа parents значение состоит из двух пар, то колонка parents умножится по количеству пар, и названия ключей сольются через .. Во втором объекте нет ключа weapon, поэтому в соответствующей строке будет проставлено NA:
## name parents.father parents.mother weapon
## 1 Thor Odin Jord Mjölnir
## 2 Loki Farbauti Laufey <NA>При импорте файла в виде списка каждый объект будет представлен в виде неименованного подсписок списка:
## List of 2
## $ :List of 3
## ..$ name : chr "Thor"
## ..$ parents:List of 2
## .. ..$ father: chr "Odin"
## .. ..$ mother: chr "Jord"
## ..$ weapon : chr "Mjölnir"
## $ :List of 2
## ..$ name : chr "Loki"
## ..$ parents:List of 2
## .. ..$ father: chr "Farbauti"
## .. ..$ mother: chr "Laufey"Если мы хотим получить имя отца Loki, то мы должны обратиться ко второму элементу списка my_json (в который мы импортировали json), так как это неименованные подсписки. Далее элементы уже имеют названия и к ним можно обращаться с помощью $ (если после $ в RStudio нажать Tab, то появится список элементов этого списка, но это работает только с именованными списками):
my_json[[2]]$parents$father## [1] "Farbauti"API
Application Programming Interface
В общем виде API (программный интерфейс приложения, application programming interface) — описание способов, которыми одна компьютерная программа может взаимодействовать с другой программой. Применительно к получению данных от сторонних сервисов через интернет — интерфейс базы данных сервиса, к которому могут обращаться разработчики приложений или третьих сервисов. В таких случаях говорят о Web API или, что корректнее, REST API.
Стандартный пример — сервис погоды. Сервис собирает и хранит данные о погоде у себя в базе данных. Однако предоставлять всем разработчикам мира доступ к базе данных неправильно (и с точки зрения безопасности, и с точки зрения архитектуры и надежности). Поэтому владельцы сервиса предоставляюи API — что-то вроде “прослойки” между внешними разработчиками и своей базой данных.
Процесс выглядит следующим образом:
разработчик делает по определенным правилам запрос к API. Правила запроса описаны в документации API, которую должен предоставить разработчик. Обычно в документации описывают ключевые элементы запроса (как и какими ключевыми словами формировать запрос), значения кодов ошибок, нередко есть “песочница” — можно в браузере попробовать собрать запрос, введя нужные значения в соответствующие поля и получить пример запроса и результат, который возвращает API на этот запрос.
API получает запрос и если запрос составлен корректно, формирует на основе этого запроса обращение к базе данных сервиса
полученная от БД информация отправляется клиенту (приложению), создавшему запрос. Как правило, для передачи информации используется формат json.
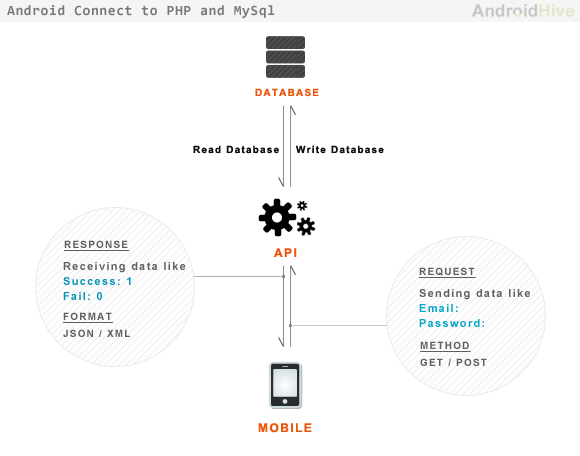
Возможные нюансы:
API может меняться (название категорий и прочие правила), а вот документацию обновить иногда забывают;
могут быть разные формы доступа - и открытый доступ, без какой-либо авторизации, либо авторизация по api_key. Нередко для авторизации используется протокол OAuth;
в подавляющем числе случаев API либо закрыты и доступ платный, либо позволяют небольшое количество тестовых запросов;
сервисы, которые предоставляют информацию, обычно имеют разные тарифные планы.
Основные шаги при работе с API
определиться с задачей
найти соответствующий сервис
найти документацию по API: на сайтах не всегда есть прямая ссылка на документацию и прочие инструменты разработчиков. Временами проще просто погуглить что-то вроде
<service name> api, например,циан apiполучить API key / пройти OAuth-авторизацию: в зависимости от требований сервиса, могут быть разные требования к процессу авторизации — надо читать документацию и условия использования сервиса.
написать GET/POST-запрос. Либо воспользоваться R-пакетом, который внутри имеет все те же get-запросы, но более дружелюбен к пользователю. В основном имеет смысл при работе с сложными сервисами типа Google Analytics API.
Accuweather
Для примера мы работаем с сервисом, предоставляющим информацию о погоде в определенных географических точках. Сервис имеет возможность искать населенный пункт по названию (в том числе и на русском языке), а также отдает текущие и прогнозные значения погоды в этой точке.
Получение api key
Начало работы выглядит следующим образом, если следовать справке на сайте:
Registration
- Click “Register” or “Sign Up” on the homepage.
- A registration form will be displayed.
- Enter the required information in the form and click the “Create new account” button to submit the form.
- An email with login instructions will be sent to the email address that you supplied in the form.
- Use the one-time login link in the email to access your account information and set your password.
Package Purchase
- Click “Packages and Pricing” in the main menu.
- Select the package you would like to purchase.
- Enter your billing information.
- Confirm purchase.
- Create an app to get your API key.
App Creation
- Click “My Apps” in the main menu.
- Click the “Add a new App” button.
- Enter the required information and click the “Create App” button.
- The new App will be active immediately. Click on the App name to view your API Key and details about your App.
- Use your API Key to access the AccuWeather APIs.
Для нас важны пункты, которые касаются создания приложения и получения API key. Приложение - это, грубо говоря, регистрация какой-то клиентской точки, с которой API будет получать запросы. При работе из R приложения как такового нет, можно сказать, что наш скрипт, который получает информацию от сервиса - своего рода такое “приложение”. В реальной жизни аткими приложениями могут встроенный виджет на сайт или в операционную систему, виджет или приложение в мобильном устройстве, какой-нибудь третий сервис по сличению и предсказанию погоды и т.д.
Помимо просто авторизации, такая архитектура позволяет владельцам сервисов управлять доступом - например, создавать различные тарифные планы с разным количеством запросов, которые можно сделать к сервису (базовый план предполагает всего 50 запросов в сутки).
Я уже зарегистрировал приложение и получил API key (ключ будет опубликован в слаке в канале general, либо у меня по запросу). Это приложение идет по отдельному тарифному плану, поэтому количества запросов должно быть достаточно для учебных целей.

GET-запрос
Первый этап работы: получение location key, внутренний идентификатор геоточки. Это можно сделать разными способами: по координатам, по списку городов (если входит в топ 150), по почтовому индексу, по текстовому поиску (который можно ограничить до страны).
Будм работать с поиском города по названию, с фильтрацией по стране. Документация по этому методу находится здесь, там же есть песочница.
Первое, что мы видим на странице — ссылка resource url. Это базовая ссылка метода API. То есть, запрос на поиск по названию и получение информации по городу состоит из этой ссылки и дополнительных параметров.
Resource url. {countryCode} — плейсхолдер для указания, в какой стране ищем город по названию.
http://dataservice.accuweather.com/locations/v1/cities/{countryCode}/searchНиже на странице есть поля для введения API key (api_key) и текстового поля, в которое вводим название города (q). Прочие параметры необязательны.
После введения этих параметров можно нажать кнопку send the request - запрос по введенным параметрам будет отправлен, и в вкладках Request, Response, cURL можно будет увидеть, какой запрос был отправлен и что было получено в ответ. Чуть ниже, в Response Error Details перечислены, какие коды ошибок может вернуть API. Это стандартные коды ответов сервера (список можно посмотреть здесь), мы ожидаем получить код 200 — запрос обработан и сервер вернул требуемую информацию.
Нас интересует вкладка cURL — на ней лучше всего видно, как и из чего формируется запрос (curl -X GET — консольная команда, сам запрос в кавычках), вместо ХХХХ должен быть API key:
http://dataservice.accuweather.com/locations/v1/cities/RU/search?apikey=ХХХХ&q=MoscowВ этом запросе вместо {countryCode} у нас стоит RU, так как мы хотим ограничить область поиска Россией. Знак ? маркирует, что после него идут параметры запроса — api_key и q (которые мы и указывали в параметрах запроса в форме). Параметры идут парой, через знак =, без пробелов: параметр=значение (например, q=Moscow). Объединение параметров происходит через знак &: apikey=ХХХХ&q=Moscow.
В вкладке Response представлен ответ сервера на запрос: это информация о клиенте, параметры запроса и собственно сам ответ сервера в виде json-объекта. Полный список параметров представлен ниже, в Response Parameters. Интересующий нас location key находится в значении ключа "Key": "294021" (для Москвы).
Соответственно, чтобы получить информацию о погоде в Москве надо использовать этот ключ в уже в других методах API, которые находятся в разделах.
GET-запросы в R
В R для создания запросов используется пакет httr и функции GET(), POST() (если предполагается отправка данных профиля клиента и запрос меняет состояние на сервере) и content() для извлечения данных из ответа сервера.
Для того, чтобы сделать запрос, необходимо собрать его из соответствующих параметров (то, что на сайте делали в формах). Так как запрос по сути строка, то для сборки запроса можно использовать разные функции склейки объектов в строки, такие как paste() или glue() пакета glue.
# подключаем пакет
library(httr)
# указываем resource url, сразу с указанием страны
city_search <-'http://dataservice.accuweather.com/locations/v1/cities/RU/search'
# указываем переменную для хранения токена, вместо XXXX должен быть реальный ключ
key <- '?apikey=XXXX'
# указываем переменную для хранения запроса названия города
search_query <- '&q=Moscow'
# собираем все в один url-запрос
city_url <- paste(city_search, key, search_query, sep = '')## [1] "http://dataservice.accuweather.com/locations/v1/cities/RU/search?apikey=XXXX&q=Moscow"Полученный url используем в функции GET(). У функции есть и другие аргументы, однако в данный момент нам достаточно одного:
city_json <- GET(url = city_url)Результат функции GET() — сложный объект, в котором интересующая нас информация хранится достаточно глубоко. Поэтому воспользуемся функцией content() все того же пакета httr, которая вернет нам json-объект в виде сложного списка с вложениями (list). Этот список должен содержать ту же информацию, которую мы получили на странице метода, когда тестировали запрос в формах:
## List of 1
## $ :List of 15
## ..$ Version : int 1
## ..$ Key : chr "294021"
## ..$ Type : chr "City"
## ..$ Rank : int 10
## ..$ LocalizedName : chr "Moscow"
## ..$ EnglishName : chr "Moscow"
## ..$ PrimaryPostalCode : chr ""
## ..$ Region :List of 3
## .. ..$ ID : chr "ASI"
## .. ..$ LocalizedName: chr "Asia"
## .. ..$ EnglishName : chr "Asia"
## ..$ Country :List of 3
## .. ..$ ID : chr "RU"
## .. ..$ LocalizedName: chr "Russia"
## .. ..$ EnglishName : chr "Russia"
## ..$ AdministrativeArea :List of 7
## .. ..$ ID : chr "MOW"
## .. ..$ LocalizedName: chr "Moscow"
## .. ..$ EnglishName : chr "Moscow"
## .. ..$ Level : int 1
## .. ..$ LocalizedType: chr "Federal City"
## .. ..$ EnglishType : chr "Federal City"
## .. ..$ CountryID : chr "RU"
## ..$ TimeZone :List of 5
## .. ..$ Code : chr "MSK"
## .. ..$ Name : chr "Europe/Moscow"
## .. ..$ GmtOffset : num 3
## .. ..$ IsDaylightSaving: logi FALSE
## .. ..$ NextOffsetChange: NULL
## ..$ GeoPosition :List of 3
## .. ..$ Latitude : num 55.8
## .. ..$ Longitude: num 37.6
## .. ..$ Elevation:List of 2
## .. .. ..$ Metric :List of 3
## .. .. .. ..$ Value : num 155
## .. .. .. ..$ Unit : chr "m"
## .. .. .. ..$ UnitType: int 5
## .. .. ..$ Imperial:List of 3
## .. .. .. ..$ Value : num 508
## .. .. .. ..$ Unit : chr "ft"
## .. .. .. ..$ UnitType: int 0
## ..$ IsAlias : logi FALSE
## ..$ SupplementalAdminAreas:List of 1
## .. ..$ :List of 3
## .. .. ..$ Level : int 2
## .. .. ..$ LocalizedName: chr "Tsentralny"
## .. .. ..$ EnglishName : chr "Tsentralny"
## ..$ DataSets :List of 7
## .. ..$ : chr "AirQualityCurrentConditions"
## .. ..$ : chr "AirQualityForecasts"
## .. ..$ : chr "Alerts"
## .. ..$ : chr "DailyPollenForecast"
## .. ..$ : chr "ForecastConfidence"
## .. ..$ : chr "FutureRadar"
## .. ..$ : chr "MinuteCast"Получить интересующий нас location key можно простым обращением к элементам списка и его подсписков:
city_key <- city_json[[1]]$Key
city_key## [1] "294021"Дополнительные материалы
Перевод неплохой статьи про основные особенности json-файлов.
Более формальная документация json.
Список 100+ сайтов API с документацией. К сожалению, немалая часть этих API сложные, требующие авторизации и многих других наюнсов. Зато понятно, насколько API распространены.
Еще один список, фактически, поиск по базе данных API, с возможностью фильтрации. Сайт (верстка) иногда глючит.
Примеры документации ЦИАН и Гисметео. Полезны в первую очередь примерами русскоязычных документаций. На сайте ЦИАН также есть интерактивная песочница, в которой можно потестировать запросы.
Домашнее задание
level 1 (IATYTD)
- Напишите функцию, которая ищет по введенному названию город и возвращает его location key.
level 2 (HNTR)
- Зарегистрируйтесь на сайте сервиса и получите свой собственный API key. Дополните функцию из предыдущего задания, чтобы можно было использовать разные api key в запросе.
level 3 (HMP)
- Напишите функцию, которая возвращает информацию о погоде на момент запроса для указанного по названию города. Функция должна принимать на вход location key города и api key. В результате функция должна возвращать табличку с датой запроса, описанием погоды, меткой, день/ночь и есть ли осадки, а так же температуру в С.
level 4 (UV)
Напишите функцию, которая принимает на вход название города и, опционально, api key. И возвращает информацию о погоде в настоящий момент в этом городе. В результате должна быть табличка с названием города, датой запроса, описанием погоды, меткой, день/ночь и есть ли осадки, а так же температуру в С.
Подумайте над архитектурой, как лучше сделать эту функцию. Может быть, следует выделит какие-то маленькие блоки или, наоборот, сделать все в одном большом блоке.